Cache latency and hit rate
With the load generator successfully run for the second time (now with caching enabled), it’s time to take another look at the time our APIs are spending reading data. You can load the dashboard by navigating to CloudWatch via the AWS console and clicking on the MomentoPizza dashboard. You can also jump directly to it here.
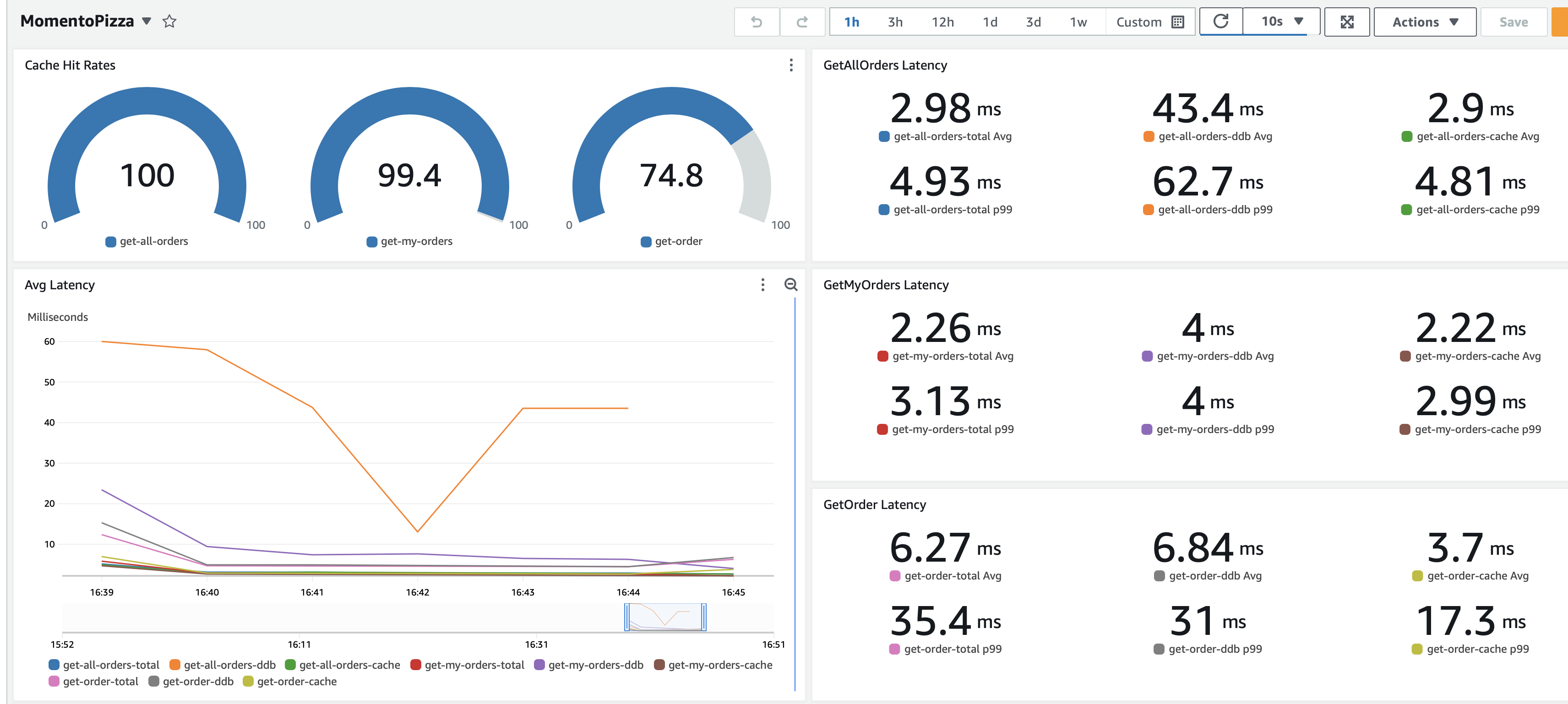
As a refresher, here is what the dashboard is able to show us…
- Time spent looking in the cache for data (now enabled)
- Time spent requesting data from the database when there is a cache miss
- Total time spent looking in the cache (now enabled), reading from the database if there’s a cache miss, and then writing the result back to the cache (now enabled)
- Cache hit rate (now enabled)
You’ll now see metrics present for additional information relating to caching. The hit rate is shown for the caching of each API endpoint along with cache read latency (average and p99). Zoom to this latest load generation run time period in the line graph to focus our investigation.
Things to observe and ponder
Referring back to the results you recorded from the earlier (non-cached) test run, consider how things have changed:
- The latency numbers for the calls to DynamoDB should remain around the same for both average and p99.
- The latency for cache reads should be significantly improved versus the DynamoDB reads (especially at p99).
- The average total latency and p99 total latency should be much improved over the same numbers for the DynamoDB component alone - close to those of the cache by itself. BUT…
- For one of our API endpoints #3 above is not true. In the case of this API, the average latency is slightly higher than for DynamoDB alone, and the p99 is only slightly improved over the p99 of DynamoDB alone. What is going on? Could this be related to the low hit rate for this API?
We can do better - let’s get back to work.